
Создайте дерево кластеризации средства для хранения вещей
Добавил пользователь Евгений Кузнецов Обновлено: 19.09.2024
Анализ ключевых слов — начальная задача при составлении любой SEO-стратегии. Когда вы определили выгодные для сайта поисковые запросы, вам предстоит отдельный этап работы по анализу собранной семантики. Кластеризация, или группировка ключевых слов — процесс, который помогает отсортировать собранные запросы, расставить приоритеты и исключить все лишнее. Это чрезвычайно важно для ранжирования — и в этой статье мы объясним почему.
Что такое кластеризация ключевых слов?
Кластеризация — это объединение похожих запросов в группы по определенному критерию и использование в оптимизации этих групп вместо отдельных ключей. С помощью кластеризации вы очищаете свое семантическое ядро, разделяя его на удобные для работы группы.
Разделение семантики на кластеры — уже давно важная часть начальных работ над сайтом. Существенным толчком стал апдейт Google под названием Колибри в 2013 году, который обозначил переход к семантической SEO — поисковик научился лучше понимать поисковые запросы и распознавать релевантные фразы вместо отдельных ключевых слов. Обновление RankBrain 2015 года укрепило тенденцию — этот алгоритм оценивает взаимодействие пользователей в поиске, он способен определять темы запросов и подбирать несколько похожих по смыслу фраз.
Существует два основных подхода к кластеризации ключевых слов:
- по семантической близости (слова группируются по смысловому и морфологическому совпадению)
- по выдаче (слова группируются по совпадениям в поисковой выдаче)
Преимущества кластеризации ключей
Кластеризация поисковых запросов даст вам представление о том, каким контентом нужно наполнять веб-страницы, на какие фразы делать упор в продвижении и как оптимизировать разные сегменты сайта.
Благодаря группировке ключей вы можете:
Ручная и автоматическая группировка ключей
Ручная группировка — это разделение каждой ключевой фразы на отдельные слова или словоформы, определение интента каждого запроса и объединение ключей в группы в соответствии с определенным параметром. Со своей стороны, автоматическая кластеризация в SE Ranking сохранит вам время и усилия, пройдя все эти этапы вместо вас и сегментируя семантику в понятные группы.
Хотя и существует множество инструментов для автоматизации процесса кластеризации, некоторые все же предпочитают делать это вручную, создавая и фильтруя списки в таблицах вроде Excel. Одно дело, когда у вас на руках сотня ключевых слов — тогда вы вполне можете их отсортировать вручную, но другое дело, когда после начального анализа у вас тысячи запросов — только представьте, сколько времени потребуется для их детального рассмотрения и группировки.
Как группировать ключевые слова в SE Ranking
Мы объяснили, зачем нужно разделять ключевые слова на тематические кластеры, и теперь перейдем к разбору специфики инструментов SE Ranking, которые помогут собрать семантику и сегментировать ее.
Начальный анализ ключей
Перед тем как заняться распределением ключей на тематические группы, нужно собрать полный их список для вашего сайта. Сбор семантики — фундаментальная задача в начале работы с любым ресурсом. Этот процесс поможет вам понять, что ищут пользователи, на которых вы ориентируетесь, и как конкуренты используют ключевые слова.


Составление групп ключей
Давайте сравним, как работает ручная и автоматическая группировка ключевых слов, а потом детальнее рассмотрим процесс кластеризации с помощью SE Ranking.
Кластеризация запросов вручную
Автоматическая группировка ключей в SE Ranking
Быстрее и эффективнее кластеризовать запросы можно с помощью инструмента SE Ranking. Для начала выберите поисковую систему (Google или Яндекс), укажите регион и язык интерфейса (для Google). Если вы планируете продвигать сайт в нескольких локациях или на разных языках, нужно будет группировать ключевые слова для каждой отдельной целевой аудитории.
После этого вам нужно выбрать точность и метод группировки — далее мы расскажем, как эти показатели влияют на результаты кластеризации. Наконец, нужно вписать сами ключевые слова — можно сделать это вручную или импортировать их из файла. SE Ranking предлагает проверять частотность ключей параллельно с их группированием — но вы также можете запустить кластеризацию без проверки частотности или же загрузить уже собранные вами показатели.
Настроив кластеризацию под свои цели и загрузив список ключевых слов, остается немного подождать, пока алгоритм SE Ranking будет искать совпадения в результатах поиска и группировать запросы по выбранному минимуму совпадений в ТОП-10.
Выбор метода и точности группировки ключей
Давайте теперь рассмотрим детальнее, как работает разный уровень точности кластеризации и чем отличаются soft и hard подходы к группировке.
На что влияет точность кластеризации
Точность кластеризации поисковых запросов — минимальное количество совпадающих страниц, ранжирующихся по ключам. Этот показатель варьируется от 1 до 9. Например, если вы поставите точность на 3, система сгруппирует вместе только те запросы, по которым есть 3 идентичные страницы в выдаче. Чем выше показатель точности, тем меньше будет совпадений и, соответственно, тем меньше ключей будет включено в кластеры.
Пример совпадений в поисковой выдаче:

Для наглядного примера мы возьмем один список из 260 ключевых слов и пропустим его через инструмент кластеризации, выбрав разные настройки. Давайте сравним результаты группировки soft методом при максимальной (9) и минимальной (1) точности.
Кластеризация высокой точности дает в результате более конкретные категории, при этом оставляя большинство фраз без группы:

Кластеры, полученные по тому же списку ключей с настройкой самой низкой точности, — более общие категории, с которыми сложнее выделить разные пользовательские интенты:

Вероятнее всего, после такой кластеризации нужно будет вручную перегруппировать многие запросы, сопоставляя их по значению или другому нужному вам критерию. В целом это всегда полезно — группировать ключевые слова и автоматически, и вручную, делая таким образом процесс максимально выверенным.
На что влияет метод кластеризации
Метод группировки (hard или soft) определяет то, как ключи будут сравниваться: метод hard сравнивает их между собой, а метод soft сопоставляет все запросы с одним, имеющим самую большую частотность (то есть с самым популярным в поиске).
Кластеризация с soft подходом дает более общее представление о нише и разных ключевых словах, используемых конкурентными сайтами. Выбрав этот метод, вы получите меньше некластеризованных ключей и, соответственно, потратите меньше времени на их досортировку.
Кластеризация с hard подходом полезна для исключения нерелевантных запросов и выявления различных интентов. Даже с самым низким уровнем точности hard кластеризация показывает большее количество конкретных интентов пользователей:


Со своей же стороны, группировка с высоким уровнем точности может упустить общее для нескольких групп.
| Количество групп | Запросы без группы | Сегментация интентов | Подходит для: | |
|---|---|---|---|---|
| Soft метод / низкая точность | Много больших групп | Среднее количество | Высокая релевант- ность внутри групп; попадание похожих ключей в разные группы | Изучения ниши |
| Soft метод / высокая точность | Среднее количество групп поменьше | Большинство | Упущены некоторые интенты | Сегментирова-ния ниши |
| Hard метод / низкая точность | Среднее количество маленьких групп | Среднее количество | Определение многих интентов; низкая релевант- ность внутри групп | Определения разных потребностей юзеров |
| Hard метод / высокая точность | Мало узкоспециали-зированных групп | Большинство | Упущены некоторые интенты; высокая релевант- ность внутри групп | Разделения ключей на максимальное количество категорий |
Последующая работа с полученными кластерами
Независимо от выбранных вами настроек система назовет каждый кластер по ключевому слову с самым большим показателем частотности. На странице результатов вы увидите данные о количестве совпавших URL-адресов и сможете просмотреть ТОП-10 выдачи по ключам из группы, а также сниппеты с этими ключами. Если вы выберете сбор частотности вместе с кластеризацией (или загрузите этот показатель самостоятельно), сгруппированные запросы также будут отсортированы по частотности.
Выбрав, какие группы ключевых слов вам подходят для дальнейшей работы, вы можете в один клик экспортировать их как внешний файл или сразу добавить в свой проект в SE Ranking. Вы также можете создавать и переименовывать группы ключей и добавлять к ним комментарии в настройках проекта. Этап работы по распределению полученных кластеров по страницам сайта уже невозможно автоматизировать — вам нужно самостоятельно анализировать, как сопоставить группы запросов со структурой вашего сайта.
Мы рекомендуем комбинировать ручную и автоматизированную группировку поисковых запросов. Проанализировав список ключей с помощью инструмента, вы увидите, как поисковые системы воспринимают эти фразы, а перегруппировав полученные кластеры вручную, сможете учесть ваши конкретные цели и структуру сайта.
Создание контента и рекламы на основе групп ключей
Прежде всего, кластеризация ключевых слов помогает лучше понять и отсортировать собранную семантику и создать эффективную структуру сайта. Вы можете выстроить иерархию страниц или же улучшить существующую исходя из полученных групп запросов. Кроме этого, кластеризация может оптимизировать процесс создания контента и рекламных объявлений.
С группами ключей вы можете максимизировать количество фраз, по которым ваш контент будет ранжироваться в поиске. Сопоставив каждую группу с определенным разделом или категорией вашего сайта и изучив все вариации запросов внутри групп, вы сможете покрыть больше пользовательских интентов. Анализ кластеров поможет вам создавать контент, соответствующий ожиданиям целевой аудитории.
Точно так же кластеризация может сделать рекламные объявления более эффективными. Google Ads позволяет создавать группы объявлений, объединяя несколько семантически подобных. Так реклама будет более актуальной для каждого пользователя, ведь Google будет выбирать то объявление из группы, которое будет самым релевантным в конкретной поисковой ситуации. В Яндексе можно создавать группы с похожими запросами (до 50) — и система будет выбирать наиболее кликабельные.
Благодаря инструментам, которые помогают быстро отсеивать лишние запросы и группировать оставшиеся по поисковой близости, вы сделаете свой контент и рекламу более полезными, а значит и продвижение сайта — более успешным.
Заключение
Семантическая кластеризация запросов — важный для SEO процесс, который поможет организовать контент по страницам сайта, покрыть больше интентов и как результат ранжироваться по большему количеству фраз.
Существуют разные подходы к кластеризации — можно группировать ключи по их значению или по совпадающим URL-адресам в выдаче. Выбирайте метод группировки (hard или soft) и уровень точности в зависимости от своих целей: изучение ниши, создание структуры сайта, скрупулезная сортировка по релевантности и т.д.
В инструменте SE Ranking вы задаете поисковую систему, локацию и язык интерфейса, выбираете метод и точность — и алгоритм сгруппирует запросы по схожести их выдачи. Автоматическая кластеризация ключевых слов сэкономит вам время и усилия и поможет проанализировать свою нишу и потребности пользователей.


Кластеризация семантического ядра - это разделение множества разнородных запросов на группы по смыслу.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA

Чтобы лучше понять, что такое кластеризация семантического ядра, можно представить подготовку белья перед стиркой. Чтобы стирка прошла быстро и продуктивно, вещи разделяют на несколько групп по цветам. А опытные хозяйки проводят сортировку белья с более подробной детализацией. В каждой цветовой группе найдутся вещи, которые нуждаются в особом температурном режиме. Их выделяют в отдельные группы. Нечто подобное происходит и при кластеризации ключевых слов. Это процесс, который превращает сотни и тысячи пользовательских запросов в упорядоченную структуру.
В идеале кластеризация ключей должна осуществляться на базе перечня свойств объектов, которые характеризуют данные ключи, а также контекста их применения. Однако на данный момент не существует открытых баз, хранящих такие сведения. По этой причине группировка ключевых слов проводится на основе поисковой выдачи.
- Получение выборки объектов для группировки.
- Задание перечня критериев оценки объектов в выборке.
- Определение степени сходства между анализируемыми объектами.
- Проведение кластерного анализа для формирования групп объектов.
- Представление результатов кластеризации.
Зачем нужно проводить кластеризацию СЯ
С помощью грамотных инструментов можно в минимальные сроки и группировать большие семантические ядра. Если в прошлом на создание ядра уходили целые месяцы, то сейчас эта работа занимает всего пару часов. Одним из преимуществ кластеризации является распределение поисковых запросов по страницам таким образом, чтобы их продвижение происходило одновременно.
Кластеризация семантического ядра позволяет получить:
- Существенную экономию времени за счет сокращения рутинной работы.
- Информационный гид по темам, популярным среди пользователей.
- План продвижения.
- Представление структуры разрабатываемого сайта.
- Объективную оценку популярности продукцию в указанной нише.
- Перечень ключей для оптимизации ресурса.
- Осуществление корректной переадресации веб-страниц.
- Создание большого хвоста поисковых запросов.
Что происходит, если не проводить кластеризацию
Если пренебречь разбиением семантического ядра сайта на кластеры, то его владелец не получит полной картины продвижения своего ресурса. Подобный результат можно получить и вследствие неправильного распределения поисковых фраз.
Вот перечень проблем, которые возникнут после некорректной группировки ключей:
- Теряется позиция в ТОПе поисковой выдачи;
- Происходит каннибализация и, как следствие, в индексах поисковиков возникает множество дублей;
- Происходит дезориентация поведенческих факторов, мешающая продвижению ресурса;
- Расходуются большие средства на создание "лишнего" контента.
Устранение и предупреждение подобных проблем - это главный ответ на вопрос: "зачем делать кластеризацию ся".
Алгоритмы кластеризации
SEO-специалисты выделяют два типа классификации алгоритмов кластеризации:
Иерархические и плоские
Иерархические алгоритмы (еще их называют алгоритмами-таксонами) формируют не одно разделение множества на пересекающиеся кластеры, а многоуровневую структуру вложенных разбиений. В результате формируется дерево кластеров. В качестве его корня выступает общая выборка, а в качестве листьев - самые мелкие группы.
Плоские алгоритмы формируют одно разделение объектов на группы.
Четкие и нечеткие
Четкие алгоритмы связывают каждый элемент выборки с номером кластера. Нечеткие алгоритмы связывают каждый элемент выборки с комбинацией вещественных значений, отражающих меру принадлежности элемента к кластерам. Таким образом каждый элемент выборки относится к каждой группе с определенной долей вероятности.
Как провести кластеризацию запросов вручную
Для ручной кластеризации семантического ядра сайта достаточно самостоятельно проанализировать ключевики и разделить их на группы. Эту работу можно облегчить с помощью инструментов Excel, LibreOffice, OpenOffice. Эти приложения позволяют работать с таблицами данных, выполнять сортировку и фильтрование по определенным параметрам.
Представленные инструменты имеют ряд достоинств:
- Универсальность - производят группировку с учетом множества разных критериев;
- Высокая точность обработки;
- LibreOffice, OpenOffice — бесплатные.
В числе их недостатков:
- Необходимость периодических бекапов;
- Низкая скорость обработки;
- Лицензионный Excel — платный.
Ручная кластеризация семантического ядра сайта более сложная и длительная по сравнению с автоматизированной. Зато можно лично проконтролировать весь процесс. Если этому уделить должное внимание, то результат качественно превзойдет автоматическую кластеризацию ся.
Автоматизированная кластеризация ся
Разделение семантического ядра на группы происходит автоматически.
Вебмастеру достаточно оценить полученные результаты. Единственным минусом такого подхода является периодически возникающее несоответствие машинной логики представлениям пользователя.
Обойти эту проблему может полуавтоматический способ группировки поисковых запросов. Для этого специалисту необходимо самостоятельно подобрать группы по полученным запросам. А автоматизированная система сама разделит запросы по указанным пользователем группам. Такой подход позволяет существенно минимизировать ошибки машинного алгоритма.
Как провести кластеризацию запросов с помощью Key Collector
Одним из лучших приложений для проведения кластеризации считается Key Collector. Программа позволяет быстро получить ключи, на основании которых будет сформировано семантическое ядро. Система может оценить конкурентность, эффективность и стоимость ключей, а также проанализировать ресурс на соответствие его контента полученному ядру.
Далее системой производится группировка запросов.
Пример кластеризации семантического ядра в системе Key Collector:
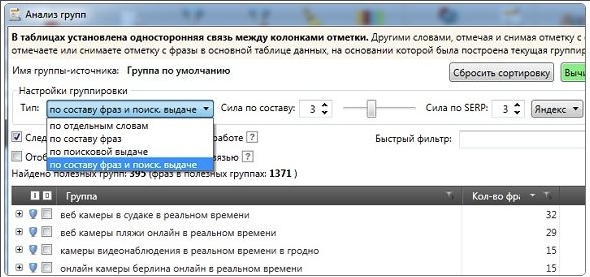
Чтобы оценить группы, которые получились, их можно выгрузить в табличный редактор (например в Excel).
Описаны четыре популярных метода обучения без учителя для кластеризации данных с соответствующими примерами программного кода на Python.

Обучение без учителя (unsupervised learning, неконтролируемое обучение) – класс методов машинного обучения для поиска шаблонов в наборе данных. Данные, получаемые на вход таких алгоритмов обычно не размечены, то есть передаются только входные переменные X без соответствующих меток y. Если в контролируемом обучении (обучении с учителем, supervised learning) система пытается извлечь уроки из предыдущих примеров, то в обучении без учителя – система старается самостоятельно найти шаблоны непосредственно из приведенного примера.

На левой части изображения представлен пример контролируемого обучения: здесь для того, чтобы найти лучшую функцию, соответствующую представленным точкам, используется метод регрессии. В то же время при неконтролируемом обучении входные данные разделяются на основе представленных характеристик, а предсказание свойств основывается на том, какому кластеру принадлежит пример.
Методы кластеризации данных являются одним из наиболее популярных семейств машинного обучения без учителя. Рассмотрим некоторые из них подробнее.
- Feature (Особенности): входная переменная, используемая для создания прогнозов.
- Predictions (Прогнозы): выходные данные модели при наличии входного примера.
- Example (Пример): строка набора данных. Пример обычно содержит один или несколько объектов.
- Label (Метки): результат функции.
Для составления прогнозов воспользуемся классическим набором данных ирисов Фишера. Датасет представляет набор из 150 записей с пятью атрибутами в следующем порядке: длина чашелистика (sepal length), ширина чашелистика (sepal width), длина лепестка (petal length), ширина лепестка (petal width) и класс, соответствующий одному из трех видов: Iris Setosa, Iris Versicolor или Iris Virginica, обозначенных соответственно 0, 1, 2. Наш алгоритм должен принимать четыре свойства одного конкретного цветка и предсказывать, к какому классу (виду ириса) он принадлежит. Имеющиеся в наборе данных метки можно использовать для оценки качества предсказания.
Для решения задач кластеризации данных в этой статье мы используем Python, библиотеку scikit-learn для загрузки и обработки набора данных и matplotlib для визуализации. Ниже представлен программный код для исследования исходного набора данных.
В результате запуска программы вы увидим следующие текст и изображение.

На диаграмме фиолетовым цветом обозначен вид Setosa, зеленым – Versicolor и желтым – Virginica. При построении были взяты лишь два признака. Вы можете проанализировать как разделяются классы при других комбинациях параметров.

Цель кластеризации данных состоит в том, чтобы выделить группы примеров с похожими чертами и определить соответствие примеров и кластеров. При этом исходно у нас нет примеров такого разбиения. Это аналогично тому, как если бы в приведенном наборе данных у нас не было меток, как на рисунке ниже.
Наша задача – используя все имеющиеся данные, предсказать соответствие объектов выборки их классам, сформировав таким образом кластеры.
Наиболее популярным алгоритмом кластеризации данных является метод k-средних. Это итеративный алгоритм кластеризации, основанный на минимизации суммарных квадратичных отклонений точек кластеров от центроидов (средних координат) этих кластеров.
Первоначально выбирается желаемое количество кластеров. Поскольку нам известно, что в нашем наборе данных есть 3 класса, установим параметр модели n_clusters равный трем.
Теперь случайным образом из входных данных выбираются три элемента выборки, в соответствие которым ставятся три кластера, в каждый из которых теперь включено по одной точке, каждая при этом является центроидом этого кластера.
Далее ищем ближайшего соседа текущего центроида. Добавляем точку к соответствующему кластеру и пересчитываем положение центроида с учетом координат новых точек. Алгоритм заканчивает работу, когда координаты каждого центроида перестают меняться. Центроид каждого кластера в результате представляет собой набор значений признаков, описывающих усредненные параметры выделенных классов.
При выводе данных нужно понимать, что алгоритм не знает ничего о нумерации классов, и числа 0, 1, 2 – это лишь номера кластеров, определенных в результате работы алгоритма. Так как исходные точки выбираются случайным образом, вывод будет несколько меняться от одного запуска к другому.
Характерной особенностью набора данных ирисов Фишера является то, что один класс (Setosa) легко отделяется от двух остальных. Это заметно и в приведенном примере.
Иерархическая кластеризация, как следует из названия, представляет собой алгоритм, который строит иерархию кластеров. Этот алгоритм начинает работу с того, что каждому экземпляру данных сопоставляется свой собственный кластер. Затем два ближайших кластера объединяются в один и так далее, пока не будет образован один общий кластер.
Результат иерархической кластеризации может быть представлен с помощью дендрограммы. Рассмотрим этот тип кластеризации на примере данных для различных видов зерна.

Можно видеть, что в результате иерархической кластеризации данных естественным образом произошло разбиение на три кластера, обозначенных на рисунке различным цветом. При этом исходно число кластеров не задавалось.
- Иерархическая кластеризация хуже подходит для кластеризации больших объемов данных в сравнении с методом k-средних. Это объясняется тем, что временная сложность алгоритма линейна для метода k-средних (O(n)) и квадратична для метода иерархической кластеризации (O(n 2 ))
- В кластеризации при помощи метода k-средних алгоритм начинает построение с произвольного выбора начальных точек, поэтому, результаты, генерируемые при многократном запуске алгоритма, могут отличаться. В то же время в случае иерархической кластеризации результаты воспроизводимы.
- Из центроидной геометрии построения метода k-средних следует, что метод хорошо работает, когда форма кластеров является гиперсферической (например, круг в 2D или сфера в 3D).
- Метод k-средних более чувствителен к зашумленным данным, чем иерархический метод.
Метод t-SNE (t-distributed stochastic neighbor embedding) представляет собой один из методов обучения без учителя, используемых для визуализации, например, отображения пространства высокой размерности в двух- или трехмерное пространство. t-SNE расшифровывается как распределенное стохастическое соседнее вложение.
Метод моделирует каждый объект пространства высокой размерности в двух- или трехкоординатную точку таким образом, что близкие по характеристикам элементы данных в многомерном пространстве (например, датасете с большим числом столбцов) проецируются в соседние точки, а разнородные объекты с большей вероятностью моделируются точками, далеко отстоящими друг от друга. Математическое описание работы метода можно найти здесь.
Вернемся к примеру с ирисами и посмотрим, как произвести моделирование по этому методу при помощи библиотеки sklearn.

В этом случае каждый экземпляр представлен четырьмя координатами – таким образом, при отображении признаков на плоскость размерность пространства понижается с четырех до двух.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise, плотностной алгоритм пространственной кластеризации с присутствием шума) – популярный алгоритм кластеризации, используемый в анализе данных в качестве одной из замен метода k-средних.
Метод не требует предварительных предположений о числе кластеров, но нужно настроить два других параметра: eps и min_samples. Данные параметры – это соответственно максимальное расстояние между соседними точками и минимальное число точек в окрестности (количество соседей), когда можно говорить, что эти экземпляры данных образуют один кластер. В scikit-learn есть соответствующие значения параметров по умолчанию, но, как правило, их приходится настраивать самостоятельно.

Об устройстве алгоритма простыми словами и о математической подноготной можно прочитать в этой статье.
Алгоритмы Google последних лет направлены на определение интентов пользователей. Искусственный интеллект распознает малейшие нюансы поисковых запросов, синонимы или предлоги.
С каждым обновлением Google становится все более литературным и близким к людям.
Учет этих апдейтов — необходимость для современных оптимизаторов. Опираться лишь на несколько целевых ключевиков, как это было ранее, сегодня мало. Надо использовать новые стратегии оптимизации контента, которые удовлетворяют запросы пользователя и соответствуют поисковым алгоритмам.
Одна из таких продвинутых стратегий — кластеризация запросов семантического ядра / ключевых слов.
Что такое кластеризация семантического ядра
Кластеризация семантического ядра — это распределение собранных ключевых запросов по тематическим кластерам. Кластеры — это группы ключевых слов, которые представляют пользователей с одинаковым поисковым намерением.

Очевидно, что стратегия с кластерами более длительная, трудозатратная. Ведь надо проанализировать больше ключей, создать больше контента. Но она стоит затраченных усилий.
Кластеризация ключевиков и создание кластеров по темам приводит ваш ресурс в соответствие с требованиями Google и делает более релевантным для пользователя.
Что дает кластеризация поисковых запросов:
Как сделать кластеризацию ключевых слов: пошаговая инструкция
Кластеризация ключевых слов — процесс небыстрый, но здесь важно понять логику. Как разделить ключи на кластеры и построить вокруг них стратегию контента — рассказываем ниже в пошаговой инструкции.
Шаг 1. Составьте список ключевых фраз
Для начала нужно собрать все ключевые слова по теме в список. В некоторых нишах их много, но без этого шага не обойтись.
Шаг 2. Определите приоритетные ключевые слова
Выберите приоритетное ключевое слово для ранжирование ресурса. Здесь можно подбирать фразы с длинным хвостом, подтемы и другие варианты расширения семантики. Найти их можно классическими способами:
- анализ конкурентов,
- автозаполнение в поиске,
- связанные запросы и под.
Шаг 3. Сведите данные вместе
Самый простой вариант оформления — таблица Excel, в которую можно внести все нужные данные в удобном формате.

Так можно рассматривать ключи в комплексе и выделить, какие из них имеют экономическую ценность.
К тому же, формат таблицы позволяет настраивать фильтры поиска, что облегчает работу с сотнями, а то и тысячами ключевых слов.
Важно: включайте в свою таблицу слова осознанно, помните, что они должны быть релевантны интентам пользователя и, как результат, конвертироваться.
Шаг 4. Разделите ключевики по группам
Приступаем к основному этапу кластеризации ключевых фраз. Большой список ключевых слов в таблице даст вам видение закономерностей: единые слова и фразы в запросах пользователей, которые могут использоваться в одинаковых ситуациях. Это и есть основа для кластеров.

При кластеризации поисковых запросов важно учитывать:
- релевантность семантики,
- объем поисковых запросов,
- сложность продвижения.
Кластер образуется вокруг основного слова и дополняется вспомогательными, подходящими по этим параметрам.

Указанный в картинке выше кластер хорош, потому что эти ключевые слова объединяются единым пользовательским интентом — найти инструмент для планирования и проведения интервью и собеседований. Основное слово дополнилось вариантами с хорошими показателями СРС и с меньшим объемом поиска.
При понимании ниши и нюансов поиска раздел на кластеры можно делать вручную или автоматически.
Инструменты и программы для автоматической кластеризации семантического ядра:
Читайте наш материал, где мы собрали Сервисы для seo-специалистов, где собраны все популярные сервисы для работы с семантикой и не только.
При кластеризации ключевиков важно помнить, что необязательно все ключи должны попасть в кластеры. Нужно брать наиболее ценные слова, то есть те, что соответствуют критериям, описанным выше.
Шаг 5. Создайте основные страницы под группы ключевых запросов
После составления кластеров на каждый из них создается своя отдельная страница. Из примера выше: один материал посвятим планированию собеседований на платформе как функции, второй — инструментам для онлайн-общения.
В курсе по Семантическому проектированию сайтов целые разделы посвящены теории и практике кластеризации запросов, а также тому, как составить максимально широкую структуру сайта.
Шаг 6. Оптимизируйте страницы для кластеров
После определения наполнения страниц приоритезируйте их по важности. И к основным материалам примените лучшие практики SEO-оптимизации контента:
- полезность и глубина исследования. Делайте лонгриды, давайте исчерпывающую информацию по теме;
- четкое структурирование: title, description, h2 и h3, нумерованные и маркированные списки;
- интерактивные элементы,улучшающие восприятие: картинки, гифки, видео, карусели.
Шаг 7. Используйте блог для укрепления кластеров
Блог — универсальный раздел, на страницах которого можно говорить о любой теме вашего сайта. Дополняйте материалы нужными ключевыми фразами и делайте перелинковку на основные опорные целевые страницы. Так их рейтинг и авторитетность будет повышаться. Больше контента — больше возможностей.
О типах, задачах и алгоритмах внутренней перелинковки на сайте, а также о ее важности для ранжирования ресурса поисковыми системами читайте в нашем материале Внутренняя перелинковка сайта.
Шаг 8. Создайте итоговую структуру содержимого сайта
После кластеризации ключевых запросов вы увидите структуру сайта с учетом предыдущих шагов. С основными целевыми страницами и ответвлениями, перелинковками и взаимосвязями контента.
Визуально это можно представить в виде схемы или ментальной карты.

Шаг 9. Внедрите стратегию в жизнь
Когда кластеризация семантики проведена, выделены основные кластеры, определена структура — наступает время классических seo-задач: поиск авторов, прописывание метатегов, загрузка контента на сайт. Если предыдущие этапы проработаны качественно, процесс реализации проходит значительно быстрей.
Как правильно заказывать SEO-тексты, детально рассказывает Игорь Рудник в рамках бесплатного курса по семантическому проектированию сайта. Также полезную информацию о кластеризации семантики вы найдете в нашем SEO курсе для новичков и в SEO книгах, где всегда есть много информации о кластеризации.
Рекомендации по кластеризации ключевых слов
Разделить на кластеры все темы в своей нише — задача непростая. Даем несколько лайфхаков, которые помогут развивать ваш проект:
- Изучите нишу на предмет интересного контента. Даже если у вас один основной продукт, детальное изучение тематических областей, интересных целевой аудитории, поможет наполнить ресурс релевантным содержанием. Результат: улучшение позиций в выдаче в меньшие сроки.
- Ведите пользователей по сайту с помощью внутренней перелинковки. Так они больше времени проведут на ресурсе, а Google будет понимать, какие страницы в приоритете.
- При подборе ключевых слов и разделении их на группы учитывайте особенности для разных рынков. Мы писали об этом в материале Создание семантического ядра.
Кластеризация ключевых слов — это стратегия SEO уровня PRO при игре вдолгую. Она помогает отстроится от конкурентов, соответствует современным требованиям поисковых систем, помогает разработать удобную и понятную структуру сайта.
Думать о ценности контента, а не только о ключах — это будущее SEO.
Читайте также: